SANTA CLARA, Calif., July 7, 2022 — A method developed by NVIDIA to reconstruct series of still images could enable users to quickly import an object into a graphics engine, where it can be further manipulated to alter its scale, material, or lighting effects. The technique, called NVIDIA 3D MoMa, demonstrated the ability to yield 3D representations of objects or scenes in a triangle mesh format that can be easily edited.
According to NVIDIA, the method supports the needs of architects, designers, concept artists, and game developers. Unlike multiview reconstruction approaches, which typically produce entangled 3D representations encoded in neural networks, NVIDIA said, the triangle meshes that NIVIDIA 3D MoMa outputs feature spatially varying materials and environment lighting that can be used in any traditional graphics engine unmodified.
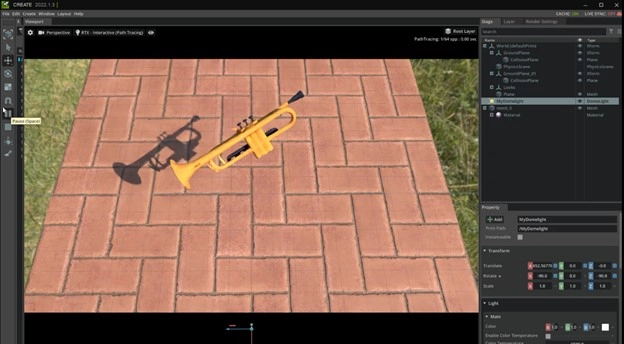
A trumpet rendered through NVIDIA's 3D MoMa technique. Courtesy of NVIDIA.
To demonstrate the capabilities of the technique, NVIDIA’s research and creative teams began by collecting around 100 images each of five musical instruments from different angles. Using that information, 3D MoMa reconstructed the 2D images into 3D representations of each instrument, represented as triangle meshes, the form typically used by game engines, 3D modelers, and film renderers.
According to David Luebke, vice president of graphics research at NVIDIA, inverse rendering, a technique to reconstruct a series of still photos into a 3D model of an object or scene, has long been a holy grail unifying computer vision and computer graphics.
The generated 3D objects would traditionally be created through complex photogrammetry techniques that require significant time and manual effort, NVIDIA said. Recent work in neural radiance fields can rapidly generate a 3D representation of an object or scene, though not in a triangle mesh format.
The objects generated through 3D MoMa are directly compatible with the 3D graphics engines and modeling tools already used by creators, meaning they can be placed directly into animated scenes and manipulated to change their texture, lighting, and scale.
A paper describing the research was presented at the Conference on Computer Vision and Pattern Recognition (https://nvlabs.github.io/nvdiffrec/assets/paper.pdf).