Deep learning applies best to problems with a wide definition of defect that can’t be simplified to counting pixels. Performing the right tests in the evaluation process will eliminate future headaches.
TOM BRENNAN, ARTEMIS VISION
Recent advancements in artificial intelligence (AI) have prompted scores of companies to invest in this type of software. This bodes well for the vision industry, as the technological leap is needed. But how will this purchase affect users at the factory who are making investments they’ll have to live with for the next decade? For them, it’s important to understand how to fairly evaluate the deep learning software options available, and how they will really work — or not.

A vision system is trained to recognize a ‘bad’ image versus a ‘good’ image for bottle labels. Courtesy of Artemis Vision.
Deep learning is applying statistics to get the greatest number of ‘right answers.’
At their core, deep learning and convolutional neural nets are layers of simple nodes that can mathematically manipulate pixels and combine those results to produce a value. A given node computes a result, which is fed into the next layer of nodes of the net. The influence of each upstream node on downstream nodes is weighted, and learning consists of relearning the proper weights to produce the outcomes the algorithm knows are correct (because people provided the training data).
In essence, end users are buying a
very powerful applied statistics engine. When it “learns,” it mathematically solves for the weightings that give the right answer. This functionality is incredibly powerful, because by clicking or launching the “relearn” process, an enormous number of calculations are triggered to deliver the desired answer. Think of it as a large, reconfigurable pinball machine with each bumper and obstacle a node. Any ball that comes in at a given velocity, spin, and vector will end up in the same place at the bottom of the machine. The pins get strategically positioned so that the good images sail right between the bottom bumpers, while good parts and everything else route to the side after hitting a variety of nodes.
Another way to think of deep learning is as an analogue to the way metrology and measurement applications must be adjusted for lens and perspective distortion. Users provide a grid with known, equal distances between points. Software mathematically warps the image until the points are all equidistant. Deep learning puts answers that users provide into a mathematical
process and then figures out the weighting of which nodes will provide that answer. Obviously, deep learning is far more complex in terms of the computations performed to render the right result, but the concept is the same.
The calibration is right, because those weights clean up distortion of the image to make all the dots equidistant. The deep learning net is right because it classifies all good images as good and all bad images as bad. The pinball machine’s pins send all the incoming balls where we would like them sent.
Wide definition of defect
There’s a mantra among vision systems professionals: Simpler and more objective is always better. That’s particularly true in a manufacturing environment. If you can mitigate the wavy background with a transform and then count pixels, do it that way. Doing it that way also makes it easy to adjust for the long run. If the customer won’t accept defects that are 10 pixels wide for a system that is 1 mm per pixel and requests a change to 8 pixels (8 mm in this example), the operator can simply make the change and rerun a few test parts.
In the case of deep learning, users can change decision thresholds or they can relabel training data and retrain and then assess the results. However, in cases where any value above x pixels in size must be rejected and below x pixels is accepted, deep learning can be problematic, as the definitions it learns tend to be fuzzier. It statistically guesses what the user cares about based on the examples. The net will ultimately produce a confidence score that results from sending the pixels through the network of computational nodes, but this confidence score does not map to a real-world characteristic. The net was trained to minimize error, and so the confidence is just the result of applying all that math to a new image.
Deep learning applies best to the problems with a wide definition of defect that can’t be simplified to counting pixels and where it’s not critical to get very precise about an acceptance threshold. If end users have that type of fuzzier problem, which is what many computer vision problems turn out to be, proceed down the deep learning path.
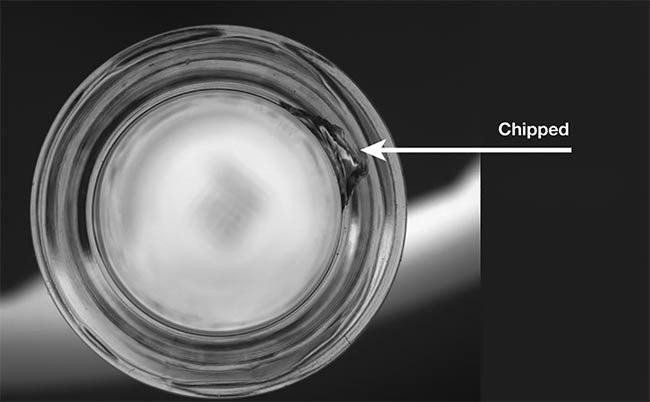

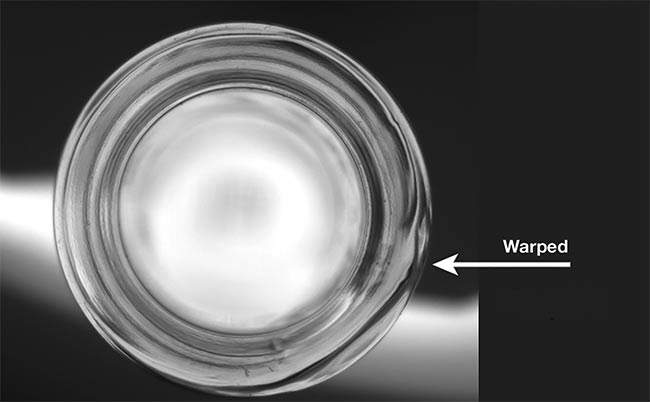
Deep learning detected three types of defects in molded glass. Courtesy of Artemis Vision.
Putting deep learning to the test
The performance of various packages can vary significantly. Prospective buyers should focus on the problem at hand; after all, they are buying a solution to a problem. Any claim of “best” is subject to real-world testing on real-world images for the type of inspection required. Quantify performance during testing to ensure the system will perform up to expectations for years to come.
Deep learning is applying statistics to get the greatest number of “right answers.” It’s important to ensure that the software has not simply memorized the test parts. This can be particularly
problematic when production is serialized and when there is a limited data set. Deep learning can memorize that the serial number is the best way to tell if the part is bad. If the system generates incorrect results on withheld data, the vendor or solution provider may go about retraining. Then they will rerun the part, which will now classify correctly, thereby “proving” that deep learning works. This is true, but with a very important caveat: What has just been proved is that the algorithm can reweigh the statistics to get the right answer. The algorithm has not proved it will work on future unseen parts, which is what you are really paying for.
For those with limited time to evaluate a system, a quick way to do so is to run a good part, induce the defect, and rerun it.
Depending on how quality-critical the application is, users may need to run only 50 parts the system hasn’t seen. It can also mean users will need to go through a process called k-fold cross-validation. In cross-validation, 1/k of the training data is withheld, and tests are performed with that data. The user conducts the test k times, so each part is withheld from training once.
What testers are looking for is the same performance each time, indicating that the result is robust. The algorithm is not sensitive to one to two training images being included in the set. The data set and the net that’s being used are going to produce the same result every time. To go back to the pinball metaphor, while each net produced isn’t exactly the same, it is functionally very similar, and the bumpers all end up in about the same place. This test also validates that the software isn’t memorizing the answers.
Perform all the withheld data tests because these prove the system will work on future parts. Before buying, deep learning should pass detailed testing with data withheld to the standard specified by the user.
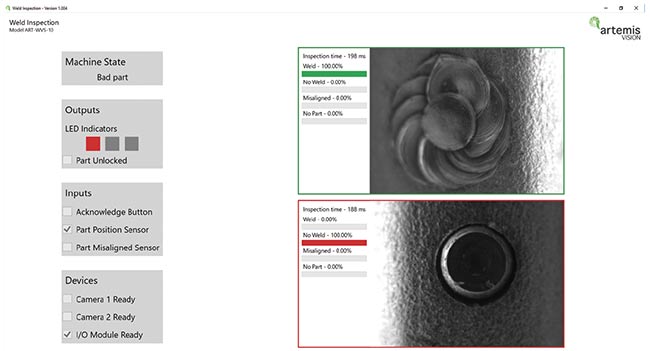
A vision system recognizes a missing weld puddle with deep learning, versus acknowledging a good weld. Courtesy of Artemis Vision.
For those with limited time to evaluate a system, a quick way to do so is to run a good part, induce the defect, and rerun the part. Ideally one could also take a defective part, fix it, and rerun the part. Both methods can give prospective buyers the confidence that the solution has learned how to find defects and not how to recognize parts. To prevent a critical quality medical error, k-fold cross-validation is the process to use.
To implement a deep learning solution fairly quickly to catch a defect that appeared on the most recent manual inspection, perfection isn’t the goal. Simply marking up a few good samples and correcting a few bad ones will give the user a level of confidence in achieving the end result.
There are some other tests users should perform to ensure they’ll get the most out of their investment for the long run. For a traditional vision system, there are established ways to recalibrate and ensure that a system is getting the same results as before.
For instance, if a camera fails, it would be replaced. Then an intensity histogram could help the user determine whether the illumination is the same, a line pattern could determine whether the focus is the same, and a calibration card could readjust for perspective and lens distortion. (Perspective distortion is going to be slightly different every time you remount a camera.) Running properly, the system would achieve the exact same results as before.
Deep learning is, in general, much more adaptable to small environmental changes than regular vision. In cases where it isn’t, the process can require a full retraining of the data set.
With the traditional vision system, a technician can go through the camera
replacement process. With deep learning inspection, the camera can be replaced, but exactly how it will perform is a little less certain. Traditional machine vision systems require a full manual that walks the operator through this process, and users want to be mathematically certain, prior to the replacement, that they will get the same results. With deep learning, end users must check that the functionality is the same with degradation of lighting and focus (which will happen over time) and that functionality is the same after swapping a camera. In theory, deep learning is much more robust to the changing conditions, but it’s important to make sure — particularly in cases where a plant is purchasing only a runtime license and cannot retrain the neural network.
Investing for the long run
Prospective buyers should back up their training data and models to replicate prior performance. Users should be able to save new images of unfamiliar defect types and retrain as needed.
Be willing to go through the retraining process or do so with the vendor as part of a reasonably priced support arrangement. Many current systems are being sold as runtime only, which is perfectly fine; however, understand that this arrangement prohibits making changes to the system down the line in the way one can with a more traditional vision system. If changes are possible, consider a training dongle or potentially an open-source neural net.
Retraining and labeling defects is surprisingly important. Remember the example of the configuration file with 8- and 10-mm defects for a traditional system. Common implementation pains with traditional machine vision can be as simple as user management, proper expectations, and proper change control processes. For instance, failure could mean a system falsely failed a few parts, which is unfortunate and something to be improved upon in the long term. However, to correct this, someone hard-keys a looser tolerance, which makes the falsely failed parts pass, thereby “fixing” the problem. But the system will now not work as intended when real defects do come.
Training data has the same power in a deep learning system. If a bad image is mislabeled as good and retrained, the algorithm will configure the weights of the nodes to make it so. The bad image and others like it now end up on the good side. This may involve “moving one bumper in the pinball machine” to cite the earlier analogy. But this leads to an unacceptable end result: Bad parts are sent to the end customer. To avoid this outcome, establish processes and procedures for when the organization will retrain the net. Otherwise, the same problem that can bedevil a traditional vision system will arise. The system needs to be readjustable and retunable (someday the light will burn out) but needs to avoid accidental retuning and readjusting. The problem is even greater in deep learning because users are no longer changing traditional tolerances (moving 8.0 to 10.0 or 12.0). A statistical engine must be retrained to produce what it was told are the right answers. In the case where we mislabel an image and retrain, we now have an algorithm training itself to produce a wrong answer.
Test, then invest
There are enormous benefits to deep
learning. Operators can short-circuit lengthy and manual algorithm development by simply training a net to automatically identify defects. The vision market is rightly skeptical, because many technologies that seem to work don’t really work in the long run on the factory floor without an engineer babysitting the system. For conventional vision systems, detailed acceptance-testing processes can catch most of these long-term issues before the system ships.
For deep learning systems, various acceptance tests are needed to make sure something works the way the end user rightfully expects it will. Better to invest with eyes wide open to the challenges and have a good set of acceptance tests than to invest naively or sit on the sidelines as others gain competitive advantage.
Meet the author
Tom Brennan is president and founder of Artemis Vision, which builds vision systems for automated inspection
and quality control. An AIA Advanced Level Certified Vision Professional,
he has worked in the industrial machine vision and imaging processing software market for the past 10 years, having delivered numerous industrial machine vision systems for industries from
medical to automotive to defense. Brennan got his start in the vision
industry designing machine vision
vehicle detection algorithms as a research effort for the DARPA Urban Challenge. He holds a BSE in computer science from Princeton University.