A full-stack optical networking platform will meet the forthcoming demands of AI model data flows, at once overcoming bandwidth, power, latency, and switching bottlenecks.
SUBAL SAHNI, CELESTIAL AI
At a time when AI processors (XPUs) are firmly in the limelight, interconnects are the true unsung heroes of AI infrastructure. This is true not only in the present, but also with an eye toward the future. With trillion-parameter generative AI models now a reality, focus has shifted from the system on chip (SoC) to the system of chips.

Courtesy of iStock.com/Henrik5000.
This shift marks a profound change in the networking technology landscape.
No longer is the principal bottleneck only the compute capability of XPUs. Now, it is also the bandwidth, latency, power, and reach of the interconnects that string these processors together so that they act in unison.
Copper’s reach as a physical medium for interconnects at current bandwidths
is limited to a few meters, even with the use of active electric cables with sophisticated retiming. Conventional optical transceiver modules are power constrained (~15+ pJ/bit) and do not offer the required bandwidth densities. Co-packaged optics solutions alleviate these problems, though only to an extent, and hence represent an incremental step toward the scale of performance and efficiency needed for forthcoming AI networks.
An optical networking platform to address these shortcomings must therefore meet the distinct challenges of the present as well as these upcoming advancements in AI networking. Given the multifaceted nature of this need, a full-stack solution that combines platform building blocks — sophisticated silicon photonics, complex application-specific integrated circuits (ASICs), and advanced 2.5D/3D packaging — presents a viable solution.
Data center networks in an AI context
Traditional data centers targeting general-purpose computing in enterprise, software as a service, and mobile applications have a networking architecture that is designed for supporting thousands of applications for millions of users. AI, which represents an entirely different kind of application,
has transformed networking design requirements due to its massive data flows, which are characterized by wide point-to-point links, high-bandwidth needs, and strict latency requirements as well as a focus on optimizing cost and power efficiency.
An AI data center essentially features four distinct types of networks (Figure 1).
The front-end network is the traditional data center network. It is used to connect compute servers to the outside world: All data that comes from cloud-based software and/or mobile applications travels back and forth using this front-end network.
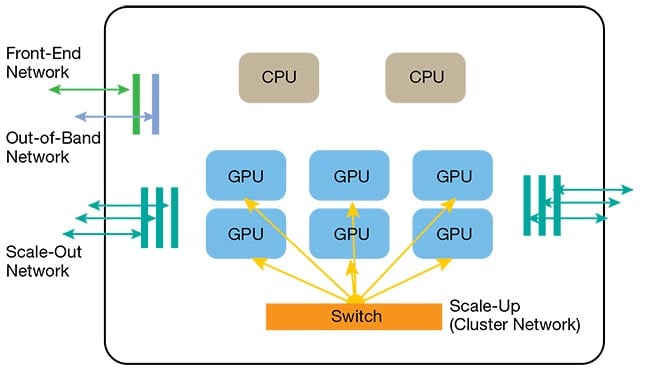
Figure 1. A conventional AI server with multiple networks comprising central processing units (CPUs) as well as graphics processing units (GPUs). Courtesy of Celestial AI.
The out-of-band network is used to
connect servers to the data center manager and to perform firmware updates, collect telemetry, and perform certain other diagnostic functions. Though the out-of-band network is a low-performance network, its function is crucial to an
optimally performing AI data center.
From an AI perspective, though, the scale-up and scale-out networks are the most important, with scale-up being the newest and arguably the most critical network given increasing model sizes.
By definition, “scale-up” means increasing the capability of a system by increasing the performance of its individual components. “Scale-out” refers to adding more components to a system to increase its capability. Together, the scale-up and scale-out networks compose what is commonly called a back-end network in AI data centers (Figure 2).
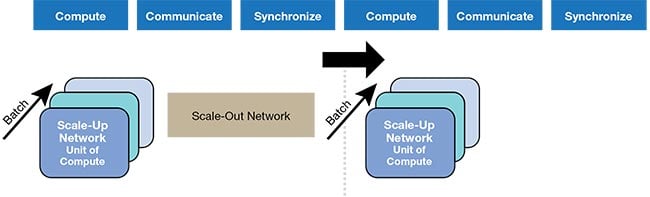
Figure 2. AI training leveraging scale-up and scale-out networks. Courtesy of Celestial AI.
Scale-up and scale-out
Today’s AI models no longer fit into the memory of a single XPU for processing.
Models have exceeded 1 trillion parameters in terms of size, which means that
one may need several terabytes of memory simply to store the model. XPUs only have limited co-packaged memory (in the range of a few hundred gigabytes), and so these models must be sharded and/or linked across multiple XPUs. Additionally, these massive models generate intermediate data and artifacts during both training and inferencing that can be hundreds of gigabytes in size, which also must be shared and moved around.
For AI training, the models are partitioned to fit into the memory of each XPU. This is carried out using tensor parallelism, whereby individual layers of a neural network are split across processors; or pipeline parallelism, whereby a model is split by layers for distribution; or a combination of the two techniques. In these partitioned models, the gradients calculated during the back-propagation phase must be synchronized to calculate updates and apply new weights. Therefore, the communication infrastructure must perform at a very high level to ensure that the XPUs always achieve high model flop usage.
Inferencing describes when a trained model is used in an application — for
example, a large language model responding to prompts. Inferencing is typically
an auto-regressive function; the current output depends on the current input plus the previous output. The previous outputs, to avoid redundant computation, are stored in a buffer memory called key value (KV) cache. Depending on the batch size and context length, the size
of the KV cache can easily be hundreds of gigabytes or even terabytes, which again necessitates the interconnection of tens to hundreds of XPUs.
It is also worth mentioning in this context that with emerging chain-of-thought models, the volume of required unified compute and memory increases significantly. This further drives the need for a high-performance interconnect between tens to hundreds of XPUs.
The network that connects these
hundreds of XPUs for both training and inference must be as high bandwidth and low latency as possible. The scale-up network provides this functionality. The scale-out network is used primarily for data parallel training, where multiple copies of the model are instantiated and different inputs are applied to each individual copy.
In practice, a scale-up network with as large a domain or cluster size as possible is desired since it enables all XPUs in the domain to act as a single “virtual super XPU,” sharing compute and memory. Today’s domain sizes are in the tens of XPUs. In the near future, meanwhile, this size will scale by a full order of magnitude.
Latency’s full effect on a given system is unlikely to be as obvious as that of bandwidth or power. But low latency is critical in all facets of AI model execution. In training, lower latency allows larger domain sizes, which enables continued scaling in the size of the models (number of parameters). And during inferencing, lower latency enables the scaling of the KV cache size, which implies longer context lengths or larger batch sizes, which in turn translates to enabling new use cases such as generative video, document summarization, inference-time compute, retrieval augmented generation, and a greater number of simultaneous users supported.
Scale-up and scale-out: A deep dive
Fundamentally, a functioning scale-up network enables all of its connected XPUs (domain) to act in unison as one single, super XPU. To do so, it must achieve a range of deliverables and exhibit certain crucial characteristics.
First, the scale-up network must provide high package bandwidth, on the order of >10 Tbps, and low latency
(approximately hundreds of nanoseconds) at low power consumption (<5 pJ/b). To support forthcoming demands, these bandwidth values should soon be scalable to several tens of terabits per second. The scale-up network must also pair with a compatible high bandwidth, low latency, medium radix switch to facilitate connections across processors.
Given the low-latency application context, the scale-up network must additionally support flit-based flow-control and routing, thereby enabling reduced latency. By contrast, Ethernet protocols — which use packet switching — are not a suitable component for low-latency applications. A scale-up network also must be scalable to hundreds of XPUs physically located across several racks, implying a reach of tens of meters.
Because a scale-out network will need to support hundreds of thousands to
possibly a million XPUs in the future, it also must meet basic, though precise, requirements. The scale-out network must first be scalable to hundreds of thousands to a million XPUs, implying a reach of hundreds of meters. It must also pair
with a high-radix switch supporting multi-tier networking to scale to the large number of endpoints. Finally, the scale-out network uses cost-efficient standards, such as Ethernet (RoCE) or InfiniBand, which implies that the bandwidth per
port is typically 400/800 Gbps in the
short term with an intermediate road map to 1.6 Tbps.
A platform solution
Given the volume (and the distinct nature) of these requirements, a single platform to directly address the gaps in current and upcoming scale-up requirements is an
essential next step — even at this point. At a fundamental level, such an optimized platform should provide an extremely high-performing optical network to an XPU package, supporting inter- and intra-chip connectivity along with full-stack support for standard electrical protocols used in chip input/output.
Realizing such a platform architecture
starts with consideration for the required
silicon photonics components. Transmitters, which typically dictate the core features of any silicon photonics platform,
use electro-absorption modulators (EAMs) that are much more compact than widely used Mach-Zehnder interferometer (MZI)-based solutions. This dramatically increases input/output density and reduces transmitter power dissipation. Additionally, EAMs have much higher thermal stability than ring-resonator-based implementations that may be used in an optical interconnect platform.
For Celestial AI, this quality of thermal stability enables the direct integration of its Photonic Fabric platform’s nodes with a high-power XPU, even with the extremely dynamic thermal environment that this presents. This combination of density and temperature resilience is
imperative for fulfilling upcoming scale-up bandwidth demands.
An additional benefit stems from the implementation of the optics in a stand-alone PIC. This decouples the PIC process node from the one that is used to build the ASICs that drive the photonics and interface with the processors in the network. In Celestial AI’s platform, these ASICs can additionally use state-of-the-art CMOS nodes to obtain the highest
possible performance and efficiency, which also allows for straightforward integration of those blocks into customer XPUs when needed. This freedom to choose a process node also enables additional downstream advantages. These
include the opportunity to achieve protocol adaptation and the flit-based flow-control referenced earlier.
Packaging technology also plays a critical role in elevating the performance of a solution. Celestial, for example, uses high-volume 2.5D/3D packaging to integrate the ASIC and the PIC, and if needed, an external XPU. But such direct packaging with an XPU is a vital feature no matter the solution properties, because it may ultimately improve die area and power consumption levels. Celestial’s
approach first aims to eliminate the need
for advanced digital signal processing
to improve the fidelity of the links to achieve these lowered consumption values.
This packaging approach can additionally eliminate the latency involved in using network interface controllers (NICs) and the need to transfer data from the XPU to the NIC over serial communication standards (such as PCIe). Combining these ingredients can also yield low-latency, medium-radix, high-bandwidth electronic switches for the scale-up networks needed to handle forthcoming data demands.
Current requirements and future gains
Current copper-based scale-up networks are incapable of meeting the upcoming
demands on bandwidth, power, and latency. Innovative photonic links with optimized switching architectures can greatly augment network performance, thereby charting a course to the anticipated next wave of AI model innovation (Figures 3 and 4). Though these solutions are still under development, substantial progress in component and system-level design, packaging, and overall usability indicates that innovation is spread across all reaches of the value chain.
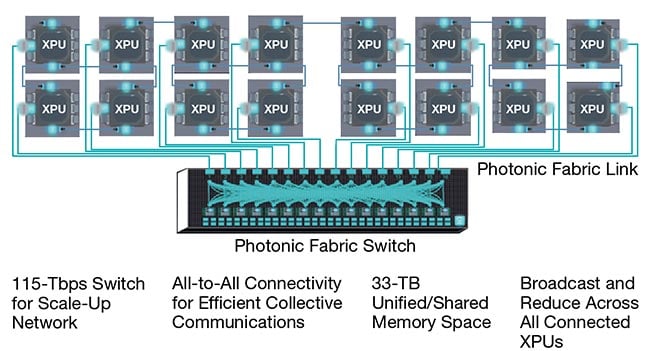
Figure 3. The Photonic Fabric platform enables cluster-scale AI processing, using high-bandwidth XPU-XPU links and electronic switches. XPU: X processor/processing unit. Courtesy of Celestial AI.

Figure 4. 128 XPU (X processor/processing unit) cluster-scale photonic fabric for accelerated computing. CPU: central processing unit; NIC: network interface card; PCIe: peripheral component interconnect express. Courtesy of Celestial AI.
Meet the author
Subal Sahni is vice president of photonics at Celestial AI. He previously held senior technical roles at Cisco Systems and Luxtera. Sahni has nearly two decades of experience in the commercialization of silicon photonics. He has authored numerous patents and publications in the field; email: [email protected].