
3D Matching and Deep Learning Transform Bin Picking
The combination of surface-based 3D matching and state-of-the-art deep learning processes makes faster and more user-friendly workflows possible.
3D-based matching, a means of determining the exact 3D location of
objects, is used in machine vision systems to optimize and automate the handling of items, allowing all types of objects to be accurately identified and located in three-dimensional space. The benefits of the method are most apparent when used for precisely determining the position and orientation of 3D objects, particularly in highly automated manufacturing scenarios involving robotics.

Courtesy of MVTec Software GmbH.
A typical application that often uses surface-based 3D matching is bin
picking, in which a robotic arm reaches into a bin and grabs specific objects. These objects may include a variety of manufactured metal parts that are ready for further processing.
The parts are captured by image-acquisition devices and have to be accurately gripped and correctly placed in the specified location by the robot. This becomes a challenge when the components overlap or are oriented
in different positions. In such cases,
the objects’ exact pose — meaning their three-dimensional rotation and translation in space — has to be determined so that they can be precisely gripped.

3D matching uses coordinates to determine object position. Courtesy of MVTec Software GmbH.
To accomplish this, the system uses and analyzes various types of digital image data, including grayscale or 3-channel RGB color images taken
by a high-resolution camera. A 3D
sensor also provides depth information for the scene. This includes the z
co-ordinates of the individual scene points, meaning the distance from
the sensor, as well as the x and y coordinates — resulting in a three-dimensional point cloud. Finally, a
CAD (computer-aided design) model is available for each object so that the system can precisely identify which part needs to be found and located.
Manual preprocessing limitations
Surface-based 3D matching is ideal for using coordinates to reliably determine the position of a particular object.
Intensive, manually generated preprocessing can optimize the application’s runtime and accuracy. But although preprocessing makes it possible to tailor the method to users’ specific requirements, this manual step significantly limits the application’s flexibility and agility. This is especially the case when a large number of different and frequently changing objects need to
be located. Manually parameterizing and fine-tuning each individual part
so that it can be reliably found requires a tremendous amount of effort. Therefore, it is extremely important to be able to successfully use surface-based matching, with as little manual pre-processing as possible.
To minimize preprocessing and improve the efficiency of the process, several challenges have to be addressed. For a first example, it makes sense when using surface-based
3D matching to keep the image background rather than remove it. Although removing it would be possible in individual applications, the 3D sensor may be installed on a robot that usually moves through the space, scanning many changing scenarios. Since the background is constantly changing, it is extremely difficult to remove.

Determining an object’s position requires grayscale or RGB images, depth information, and a CAD (computer-aided design) model. Courtesy of MVTec Software GmbH.

Multiple overlapping objects make matching more difficult. Courtesy of MVTec Software GmbH.
A second challenge is the need to avoid manually separating the objects and segmenting them ahead of time. Although this type of manual preprocessing increases the speed and accuracy of surface-based 3D matching, it also limits the range within which the corresponding applications can be used successfully, as mentioned. A third challenge is the need to minimize
the number of parameters to be adapted. The machine vision application must be able to find all conceivable objects in all possible scenes using the same parameters. Once these three challenges are met, surface-based matching can be used with a wide range of objects and scenarios.
Incorrect pose recognition
Nevertheless, model experiments have shown that in certain situations, finding and determining the position of objects can be problematic. The reasons often relate to material properties. Metal objects in particular can cause problems if they are highly reflective. If the relevant part is oriented in an unfavorable position, the sensor’s projection pattern may be reflected directly into the camera. This creates local overexposure, with the result that the sensor cannot perform a reconstruction at this location, and it is also unable to supply
3D information. However, regular surface-based matching only uses the information in the 3D point cloud to fit the model into the scene. If the sensor cannot provide this data, matching
cannot be performed successfully.
Consequently, there are cases where surface-based matching is unable to find objects at the correct location without additional preprocessing. This could result in the robot being unable to grip the object accurately or position it correctly. In some cases, problems can also be caused by the relatively long runtime that results from having to search through a comparatively large background. The matching operation then takes up most of the available cycle time. Since each object class adds to the runtime, the execution time ends up being too long for most applications.
Limiting the search region
Reducing the search region is one means of making matching processes more efficient and achieving better search results. Limiting the search space to the approximate region of the object not only enables a robot to find objects more successfully but also accelerates the matching process, with an execution time of a few milliseconds. Nevertheless, defining the search area has to be performed as part of manual preprocessing which, as mentioned above, involves a significant effort. Less effort is required when the image background is largely homogeneous and the object clearly stands out against it.
For more complex applications, however — where a large number of parts overlap or have different textures, or when the background has a heterogeneous structure — more
effort is required. Preprocessing is also made more difficult by differences in lighting, or by the presence of many types of objects, or by interfering objects that are not the target of the search. In these cases, separating the objects would require manual adaptations for each object, which again increases effort. In such complex application scenarios,
it is difficult to find a simple manual solution that can
successfully limit the search areas for a wide range of scenes and objects.
More efficient search processes with AI
A practical solution to this problem is artificial intelligence (AI) and especially deep learning, which is based on convolutional neural networks (CNNs). These technologies are already an integral element of modern, standard machine
vision software, as in the case of MVTec’s HALCON software.
Normally, limiting the search region must be done as part of expensive manual preprocessing. With the aid of deep learning processes, however, this manual step becomes much more efficient. A major advantage of deep learning
is the concept of end-to-end learning. Instead of manually defining the features or combinations of features for each
target object, the deep learning algorithm independently works out the most prominent and descriptive features for each class or object by analyzing training data. Thus, on the basis of diverse training data, a generic model can be trained, which can then locate many different objects in 2D image data with extreme accuracy.
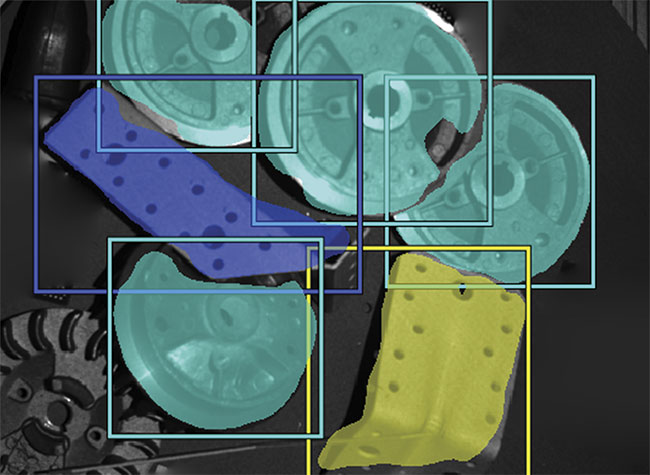

Object regions found by means of deep learning enable more efficient 3D-matching processes. Courtesy of MVTec Software GmbH.
Deep learning processes can, for example, serve as a preprocessing step for pre-locating the objects to be gripped. In this case, a deep learning-based
segmentation approach is applied to the existing 2D image data. Segmentation provides a pixel-precise region for each object class in the image. When this step is combined with a deep learning-based object detection method that predicts a rectangle around each object, a pixel-precise region can be determined for each individual object. This region describes the image area containing the relevant object. The point cloud can then be
reduced based on the known correlation between 2D image data and 3D data. This means that only 3D data relating to the regions identified in the 2D image can be used for further processing. As a result, surface-based 3D matching is performed on only a fraction of the data, making it possible to significantly reduce the runtime. Pre-segmentation based on 2D data also permits an even more robust pose estimation of objects. In conclusion, the creative use of deep learning methods provides a highly efficient form of preprocessing for surface-based matching.
Generation of training data
The greatest challenge when training deep learning models is finding suitable training data. First of all, the training images must be as similar as possible to the real images of the application. The objects to be learned must also be
labeled, meaning that a pixel-precise region or surrounding rectangle (bounding box) must be provided. In many cases, however, capturing enough images and manually labeling each object in order to train a suitable
model is a difficult and laborious
process.
One possible solution to both of these issues is to generate artificial data. For example, 3D models of the objects can be used and rendered in 2D images. However, the training images of the rendered objects are very different from the real images, and the trained deep learning model is not perfectly transferable to the application. A better alternative is to capture the objects of interest individually and in various positions on a homogeneous background. Automatically segmenting the objects in these images is then simple. The region can be cropped and pasted on any background. This makes it easy to simulate even complex, real images that contain multiple objects quite accurately. These partly artificial, partly real images are well suited for training deep learning models, without having to invest a great deal of time and effort in labeling.
By cleverly combining traditional methods and deep learning technologies, users can not only make the results of their 3D-matching application even more accurate, but they can do so with faster execution times. In fact, anyone who works with challenging machine vision applications should consider such hybrid approaches to achieving more robust results, faster execution times, and shorter time to market.
Meet the author
Rebecca König is a research engineer at MVTec Software GmbH. She has a master’s degree in mathematics from the Technical University of Munich, and she joined MVTec’s research department in 2017. König works primarily on deep learning and 3D methods; email: [email protected].
/Buyers_Guide/MVTec_Software_GmbH/c9954