Digital imaging provides the means to enhance features of interest while attenuating details that are irrelevant to a given application, and then extracts useful information about the scene from the enhanced image.
William Silver, Cognex Corp.
Images are produced by many means: cameras, x-ray machines, electron microscopes, radar and ultrasound. They are used in the entertainment, medical, scientific and business industries; for security purposes; and by the military and government. The goal in each case is for a human or machine observer to extract useful information about a scene (Figure 1).

Figure 1. Digital image processing is used to verify that the correct tire is installed on vehicles at GM.
Often the raw image is not directly usable and requires processing, which is called image enhancement. When processed by an observer to extract information, it is called image analysis. Enhancement and analysis are distinguished by their output, images vs. scene information, and by the challenges faced and methods employed.
Image enhancement has been done by chemical, optical and electronic means, while analysis has been done mostly by humans and electronically.
Digital image processing is a subset of the electronic domain, where the image is converted into an array of small integers, called pixels. The pixels represent a physical quantity such as scene radiance, which is stored in a digital memory and processed by computer or other digital hardware. Digital image processing, either as enhancement for human observers or for autonomous analysis, offers advantages in cost, speed and flexibility and, with the rapidly falling price and rising performance of personal computers, has become the dominant method.
The challenge
An image is not a direct measurement of the properties of physical objects. Rather, it is a complex interaction of several physical processes: the intensity and distribution of illuminating radiation, the physics of the interaction of the radiation with the matter composing the scene, the geometry of projection of the reflected or transmitted radiation from three dimensions to the two dimensions of the image plane, and the electronic characteristics of the sensor. Unlike writing a compiler, for which an algorithm backed by formal theory exists to translate a high-level computer language to machine language, there is no algorithm and no comparable theory for extracting scene information of interest such as position or quality from an image.
The challenge is often underappreciated because of the seeming effortlessness with which the human visual system extracts information from scenes. Human vision is more sophisticated than anything we can engineer and will remain so for the foreseeable future. Thus, care must be taken not to evaluate the difficulty of a digital image processing application on the basis of how it looks to humans.
Perhaps the first guiding principal should be that humans are better at judgment and machines are better at measurement. Thus, determining the precise position and size of an automobile part on a conveyor, for example, is well-suited to digital image processing, whereas grading apples or wood is more challenging. Along these lines, image enhancement, which requires much numeric computation but little judgment, is well-suited to digital processing.
If teasing useful information out of an image that looks like soup is not challenging enough, the problem is further complicated by time constraints. Few users care if a spreadsheet takes 300 ms to update rather than 200, but most industrial applications operate within limits imposed by machine cycle times. There are also many applications, such as ultrasound image enhancement, traffic monitoring and camcorder stabilization, that require real-time processing of a video stream.
To make the speed challenge concrete, consider finding a pattern in an image by the simple method of examining every possible position of the pattern in the image and determining which position is most similar to the pattern. If the pattern is 125 × 125 pixels and the image is 640 × 480, there are 516 × 356 = 183,696 positions and 15,625 pixel pairs to analyze at each position, for a total of about 2.87 billion pixel pairs. If each pixel pair analysis needs 5 arithmetic operations and the work needs to be done in 10 ms, one would need a computer capable of about 1.4 trillion operations per second, over 100 times beyond the reach of desktop PCs as of 2003. This example is fairly typical of industrial requirements. Now imagine that the pattern can also rotate up to 360°!
On top of this, many digital image processing applications are constrained by severe cost targets. This presents the engineer with the dreaded triple-curse: the need to design something that is simultaneously good, fast and cheap.
Hardware
Lights — All image processing applications start with illumination, typically light. In some cases, ambient light must be used, but, more typically, illumination is designed for the application. The battle is often won or lost right here — no software can recover information that isn’t there as a result of poor illumination.
Generally, one can choose intensity, direction, spectrum (color), and continuous or strobed illumination. Intensity is easiest to choose and least important; any decent image processing algorithm should be immune to significant variations in contrast, although applications that demand photometric accuracy will require control and calibration of intensity.
Direction is more difficult and more important. The choices range from point sources at one extreme to sky illumination (equal intensity from every direction) at the other. In between are various extended sources, such as linear lights and ringlights.
The goal often is to produce consistent appearance. As a rule, matte surfaces do better with point sources, and shiny, specularly reflecting surfaces do better with diffuse, extended sources. A design that allows computer-controlled direction (usually by switching light-emitting diodes on and off) is often ideal.
Illumination color can be used as a form of image enhancement. Its primary value is that it is cheap and does not increase the processing time.
High-speed image acquisition for rapidly moving or vibrating objects may require a strobe. Most cameras have an electronic shutter, which is preferable for low- to medium-speed acquisition, but as the exposure times get shorter, the amount of light needed increases beyond what is reasonable to supply continuously.
Camera — For our purposes, a camera is any device that converts a pattern of radiated energy into a digital image stored in random access memory. In the past, this operation was divided into two pieces: conversion of energy to electrical signal (considered to be the camera’s function) and conversion and storage of the signal in digital form, performed by a digitizer. The distinction is becoming blurred, and before long cameras will feed directly to computer memory via USB, Ethernet or IEEE-1394 interfaces.
Camera technology and the characteristics of the resulting images are driven almost exclusively by the highest volume applications, which, until recently, had been consumer television. Thus, most visible light cameras in use for digital image processing have resolution and speed characteristics that were established by TV broadcast standards almost a half-century ago.
Today, the typical visible light monochrome camera has a resolution of 640 × 480 pixels, produces 30 to 60 frames per second (fps), and supports electronic shuttering and rapid reset (the ability to reset to the beginning of a frame at any time to avoid the wait before beginning an image acquisition). It is based on charge-coupled device (CCD) sensor technology, which produces good image quality but is expensive relative to most chips with a similar number of transistors.
Significantly higher resolution and speed devices are available but often are prohibitively expensive. An alternative is the line-scan camera, which uses a one-dimensional sensor and relies on scene motion to produce an image.
For the first time, the landscape is changing as high-volume personal computer multimedia applications proliferate. First affected were monitors, which for some time had offered higher-than-broadcast speed and resolution. One can expect cameras to follow with high-speed, high-resolution devices driven by consumer digital still-camera technology and lower resolution, ultralow-cost units driven by entertainment, Internet conferencing and perceptual user interface applications.
The low-cost devices may have the greater influence. These are based on emerging complementary metal oxide semiconductor (CMOS) sensor technology, which uses the same process as most computer chips and is therefore inexpensive because of higher process volume. Image quality is not up to CCD standards yet, but that is certain to change as the technology matures.
Although monochrome images have disappeared almost entirely in consumer applications, they still represent the majority in digital image processing because of camera cost and the data processing burden. Color cameras come in two forms: single-sensor devices that alternate red, green and blue (RGB) pixels in some pattern, and much higher quality but more expensive devices with separate sensors for each color.
Monochrome pixels are usually 8 bit (256 gray levels), although 10-and 12-bit devices are sometimes used. Video signals tend to be noisy, however, and careful engineering is required to get more than eight useful bits out of the signal. Also, robust image analysis algorithms do not rely on photometric accuracy, so unless the application calls for accurate measurements of the scene radiance, there is usually little or no benefit beyond 8 bits. Wide dynamic range is more useful than photometric accuracy, but it is usually best achieved by using a logarithmic response than by going to more bits.
Color pixels are 3-vectors (this is a fact of human physiology, not physics). Several representations, called color spaces, are commonly used to represent color. The simplest to produce is the RGB space, although hue, intensity and saturation (HIS) may be more useful for image analysis. For lower quality single-sensor cameras, the luminance, chroma1 and chroma2 space (YCC) is sometimes used.
Action — Until the late 1990s, the computational burden of digital image processing rested with dedicated hardware, which consisted of plug-in cards for PCI and/or VME backplanes containing one or more application-specific integrated circuits.
Since that time, vendors have moved from dedicated hardware to pure software solutions because of the advent of digital signal processors (DSPs) and general-purpose central processing units that fall at or above the 1 billion operations per second mark. Of these, the most significant has been the development of the MMX processors by Intel Corp.
MMX, though not the only usable technology, is so widely available (it has been incorporated into all Intel-telcompatible PCs made since 1997) that it is the de facto standard for merchant digital image processing software. Challenging PCs for dominance are newer DSPs, which, although not quite as fast, are much lower in cost. These DSPs are being built into very inexpensive and easy-to-use machine vision sensors that are a far better choice in almost any application that does not require a PC for other reasons.
The full power of the new processors generally is available only to skilled assembly language programmers, which is unlikely to change in the foreseeable future. Compiler vendors and computer architects may argue otherwise, but direct experience in high-performance digital image processing has consistently shown this to be the case. For time critical applications, users should turn to specialists.
Algorithms
Discussion of digital image processing algorithms can be divided into image enhancement and image analysis. The distinction is useful if not always clear-cut.
Image enhancement algorithms often produce modified images intended for subsequent analysis by humans or machines. Their output behavior and execution speed are easy to characterize, and the basic algorithms are generally in the public domain.
Image analysis, by contrast, produces information that is smaller in quantity but more highly refined than an image, such as the position and orientation of an object. In many cases, the output is an accept/reject decision — the smallest quantity of information but perhaps the highest refinement. Output behavior and execution speed are difficult and sometimes impossible to characterize. Image analysis algorithms are often a vendor’s most important intellectual property.
An example drawn from human experience makes these points. Imagine focusing a lens, which is an act of image enhancement. It is easy to characterize what will happen — the picture gets sharper — and estimate how long it will take — a couple of seconds. The results will be fairly consistent from person to person, and there is no great secret as to how it is done.
Now imagine that you are shown a picture of a specific car and are asked to find it in a parking lot and report its space number. This is image analysis. If the lot is nearly empty, the results and the time needed are consistent and easy to characterize. If the lot is full, however, there is no telling how long it will take or even whether the correct answer will be reported, since many cars look alike. Characterizing the output space number as a function of the input distribution of scene radiance measurements is essentially impossible. Results may vary widely from person to person, and an individual’s proprietary methods may have a large bearing on the outcome.
The difficulty in characterizing the behavior of automated image analysis leads to a level of risk that is far greater than that of more typical — and risky — software development projects. The best ways to manage the risk are to rely on experienced professional developers, to share the risk between vendors and their clients, and to characterize performance empirically using a large database of stored images.
Image Enhancement — Table 1 shows a classification of common digital image enhancement algorithms. The classification given is useful but neither complete nor unique. The algorithms are broadly divided into two classes — point transforms and neighborhood operations.
TABLE 1.
IMAGE ENHANCEMENT ALGORITHMS
|
Point Transforms |
|
Neighborhood Operations |
| |
• Pixel mapping |
|
• Linear filtering |
• Nonlinear filtering |
| |
Gain/offset control |
|
Smoothing |
Median filter
|
| |
Histogram specification |
|
Sharpening |
Morphology
|
| |
Thresholding |
|
• Boundary detection |
• Resampling |
| |
• Color space transforms |
|
|
Resolution pyramids
|
| |
• Time averaging |
|
|
Coordinate transforms
|
Point transforms produce output images where each pixel is some function of a corresponding input pixel. The function is the same for every pixel and is often derived from global statistics of the image. With neighborhood operations, each output pixel is a function of a set of corresponding input pixels. This set is called a neighborhood because it is usually some region surrounding a corresponding center pixel; for example, a 3 × 3 neighborhood.
Point transforms execute rapidly but are limited to global transformations such as adjusting overall image contrast. Neighborhood operations can implement frequency and shape filtering and other sophisticated enhancements, but they are executed more slowly because the neighborhood must be recomputed for each output pixel.
Pixel-mapping point transforms include a large set of enhancements that are useful with scalar-valued pixels such as monochrome images. Often, these are implemented by a single software routine, or hardware module, that uses a lookup table. Lookup tables are fast and can be programmed for any function, offering the ultimate in generality at reasonable speed. MMX and similar processors, however, can perform a variety of functions much faster with direct computation than table lookup, at a cost of increased software complexity.
Pixel maps are most useful when the function is computed based on global statistics of the image. One can process an image to have a desired gain and offset, for example, based on the mean and standard deviation or, alternatively, the minimum and maximum of the input.
Histogram specification is a powerful pixel-mapping point transform wherein an input image is processed so that it has the same distribution of pixel values as some reference image. The pixel map for histogram specification is easily computed from histograms of the input and reference images. It is a useful enhancement prior to an analysis step whose goal is some sort of comparison between the input and the reference.
Thresholding is a commonly used enhancement whose goal is to segment an image into object and background. A threshold value is computed above (or below) which pixels are considered “object” and below (or above) which are considered “background.” Sometimes, two thresholds are used to specify a band of values that correspond to object pixels. Thresholds can be fixed, but are best computed from image statistics. Thresholding can also be done using neighborhood operations. In all cases, the result is a binary image; only black and white are represented, with no shades of gray.
Thresholding has a long but checkered history in digital image processing. Up until the mid-1980s, thresholding was the nearly universal first step in image analysis because of the high cost of hardware needed for grayscale processing. As hardware costs dropped and sophisticated new algorithms were developed, thresholding became less important.
When thresholding works, it can be quite effective because it directly identifies objects against a background and eliminates unimportant shading variations. Unfortunately, in most applications, scene shading is such that objects cannot be separated from background by any threshold, and, even when an appropriate threshold value exists in principal, it is notoriously difficult to find automatically. Furthermore, thresholding destroys useful shading information and applies essentially infinite gain to noise at the threshold value, resulting in a significant loss of robustness and accuracy.
Given the performance of modern processors and gray-scale image analysis algorithms, thresholding and image analysis algorithms that depend on thresholding are best avoided.
Color space conversion is used to convert, for example, the RGB space provided by a camera to the HIS space needed by an image analysis algorithm. Accurate color space conversion is computationally expensive and often, crude approximations are used in timecritical applications. These can be quite effective, but it is a good idea to understand the trade-offs between speed and accuracy before choosing an algorithm.
Time averaging is the most effective method of handling lowcontrast images. Pixel maps to increase image gain are of limited utility because they affect signal and noise equally. Neighborhood operations can reduce noise but at the cost of some loss in image fidelity. The only way to reduce noise without affecting the signal is to average multiple images over time. The amplitude of uncorrelated noise is attenuated by the square root of the number of images averaged. When time averaging is combined with a gain-amplifying pixel map, extremely low contrast scenes can be processed. The principal disadvantage of time averaging is the time needed to acquire multiple images from a camera.
Linear filters are the best understood of the neighborhood operations because of the extensively developed mathematical framework of signal theory dating back 200 years to Fourier. Linear filters amplify or attenuate selected spatial frequencies, can achieve such effects as smoothing and sharpening, and usually form the basis of resampling and boundary-detection algorithms.
Linear filters can be defined by a convolution operation, where output pixels are obtained by multiplying each neighborhood pixel by a corresponding element of a like-shaped set of values called a kernel, and then summing those products.

Figure 2. An image can be enhanced to reduce noise or emphasize boundaries.
Figure 2a shows a rather noisy image of a cross within a circle. Convolution with the smoothing (low-pass) kernel of Figure 2b produces Figure 2c. In this example, the neighborhood is 25 pixels arranged in a 5 × 5 square. Note how the high-frequency noise has been attenuated, but at a cost of some loss of edge sharpness. Note also that the kernel elements sum to 1.0 for unity gain.
The smoothing kernel of Figure 2b is a 2-D Gaussian approximation. The 2-D Gaussian is among the most important functions used for linear filtering. Its frequency response is also a Gaussian, which results in a well-defined bandpass and no ringing. Kernels that approximate the difference of two Gaussians of different size make excellent bandpass and high-pass filters.
Figure 2d illustrates the effect of a bandpass filter based on a difference of Gaussian approximation using a 10 × 10 kernel. Note that both the high-frequency noise and the low-frequency uniform regions have been attenuated, leaving only the midfrequency components of the edges.
Linear filters can be implemented by direct convolution or in the frequency domain using fast Fourier transforms (FFT). While frequency-domain filtering is theoretically more efficient, in practice direct convolution is almost always preferred. Convolution, with its use of small integers and sequential memory addressing, is a better match for digital hardware than FFTs. It is also simpler to implement and has little trouble with boundary conditions.
Boundary detection has an extensive history and literature that ranges from simple edge detection to complex algorithms that might be considered more properly under image analysis. We somewhat arbitrarily consider boundary detection under image enhancement because the goal is to emphasize features of interest — the boundaries — and attenuate everything else.
The shading produced by an object in an image is among the least reliable of an object’s properties, since shading is a complex combination of illumination, surface properties, projection geometry and sensor characteristics. Image discontinuities, on the other hand, correspond directly to object surface discontinuities (e.g., edges), since the other factors tend not to be discontinuous. Image discontinuities are consistent geometrically, or in shape, even when not consistent photometrically (Figure 3). Thus, identifying and localizing discontinuities, which is the goal of boundary detection, is one of the most important digital image processing tasks.

Figure 3. Image discontinuities usually correspond to physical object features, whereshading is often unreliable.
Boundaries usually are defined as points where the rate of change of image brightness is at a local maximum; i.e., at peaks of the first derivative or, equivalently, zero-crossings of the second derivative. On a discrete grid, these points can only be estimated with linear filters designed to estimate first or second derivative. The difference of the Gaussian of Figure 2d, for example, is a second derivative estimator, and boundaries show up as zero-crossings that occur at the sharp black-to-white transition points in the figure.
Figure 2e shows the output of a first-derivative estimator, often called a gradient operator, applied to a noise-free version of Figure 2a. The gradient operator consists of a pair of linear filters designed to estimate the first derivative horizontally and vertically, which gives components of the gradient vector. The figure shows gradient magnitude, with boundaries defined to occur at the local magnitude peaks.
Crude edge detectors simply mark the image pixels that correspond to gradient magnitude peaks or second-derivative zero-crossings. Sophisticated boundary detectors produce organized chains of boundary points, with subpixel position and boundary orientation accurate to a few degrees at each point. The best commercially available boundary detectors are also tunable in spatial frequency response over a wide range and operate at high speed.
Nonlinear filters designed to pass or block desired shapes rather than spatial frequencies are useful for digital image enhancement. The first we consider is the median filter, whose output at each pixel is the median of the corresponding input neighborhood. Roughly speaking, the effect of a median filter is to attenuate image features smaller in size than the neighborhood and to pass image features larger than it.
Figure 2f shows the effect of a 3 × 3 median filter on the noisy image of Figure 2a. Note that the noise, which often results in features smaller than 3 × 3 pixels, is strongly attenuated. Unlike the linear smoothing filter of Figure 2c, however, there is no significant loss in edge sharpness, since all of the cross and circle features are much larger than the neighborhood. Thus, a median filter is often superior to linear filters for noise reduction. One of the main disadvantages of the median filter, however, is that computations are more expensive with it than with linear filters, and the disparity gets worse as the neighborhood size increases.
Morphology refers to a broad class of nonlinear shape filters. As with linear filters, the operation is defined by a matrix of elements applied to input image neighborhoods, but, instead of a sum of products, a minimum or maximum of sums is computed. These operations are called erosion and dilation, and the matrix of elements is usually referred to as a probe rather than a kernel.
Erosion followed by a dilation using the same probe is called an opening, and dilation followed by erosion is called a closing.
The four basic morphology operations have many uses, one of which is shown in Figure 4. In this figure, the input image on the left is opened with a circular probe and a rectangular probe, resulting in the images shown on the right. Imagine the probe to be a paintbrush, with the output being everything the brush can paint when it is placed wherever in the input it will fit (i.e., entirely on black with no white showing). Notice how the opening operation with appropriate probes can pass certain shapes and block others.
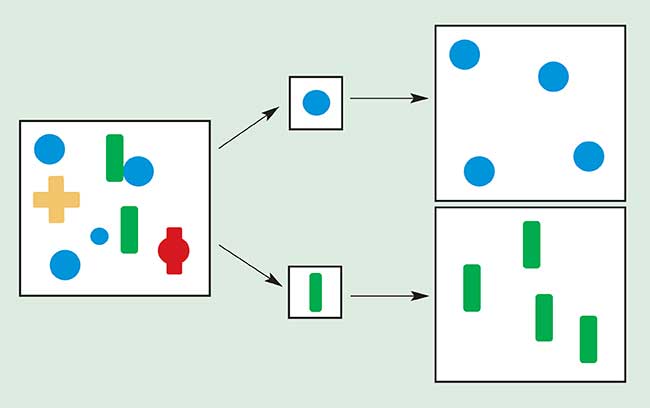
Figure 4. A morphology “opening” operation acts as a shape filter, whose behavior is controlled by a probe.
For simplicity, the example of Figure 4 illustrates opening as a binary (black/white) operation, but, in general, the four are defined on gray-level images, with the concept of probe fitting defined on 2-D surfaces in 3-space.
Digital resampling refers to a process of estimating the image that would have resulted had the continuous distribution of energy falling on the sensor been sampled differently. A different sampling, perhaps at a different resolution or orientation, is often useful.
One of the most important forms of digital resampling obtains a series of images at successively coarser resolution, called a resolution pyramid. Conventionally, each image in the series is half the resolution of the previous in each dimension (1/4 the number of pixels), but other choices are often preferable. Resolution is reduced by a combination of low-pass filtering and subsampling (selecting every nth pixel).
A resolution pyramid forms the basis of many image analysis algorithms that follow a coarse-to-fine strategy. The coarse resolution images allow rough information to be extracted quickly, without being distracted and confused by fine and often irrelevant detail. The algorithm proceeds to finer resolution images to localize and refine this information.
Another important class of resampling algorithms is coordinate transforms, which can shift by subpixel amounts, rotate and size images, and convert between Cartesian and polar representations. Output pixel values are interpolated from a neighborhood of input values. Three common methods are nearest neighbor, which is the fastest; bilinear interpolation, which is more accurate but slower and suffers some loss of high-frequency components; and cubic convolution, which is very accurate but the slowest.
Image analysis
It is only a slight oversimplification to say that the fundamental problem of image analysis is pattern recognition, the purpose of which is to recognize image patterns corresponding to physical objects in the scene and to determine their pose (position, orientation, size, etc.). Often, the results of pattern recognition are sufficient; for example, a robot guidance system supplies an object’s pose to a robot. In other cases, a pattern recognition step is needed to find an object so that it can be inspected for defects or correct assembly.
Pattern recognition is difficult because a specific object can give rise to a wide variety of images depending on all of the factors previously discussed. Furthermore, similar-looking objects may be present in the scene that must be ignored, and the speed and cost targets may be severe.
Blob analysis is one of the earliest methods widely used for industrial pattern recognition. The premise is simple: Classify image pixels as object or background by some means, join the classified pixels to make discrete objects using neighborhood connectivity rules, and compute various moments of the connected objects to determine object position (1st moments), size (0th moment), and orientation (principal axis of inertia, based on 2nd moments).
The advantages of blob analysis include high speed, subpixel accuracy (in cases where the image is not subject to degradation), and the ability to tolerate and measure variations in orientation and size. Disadvantages include the inability to tolerate touching or overlapping objects, poor performance in the presence of various forms of image degradation, the inability to determine the orientation of certain shapes and poor ability to discriminate among similar-looking objects.
Perhaps the most serious problem, however, is that the only reliable method ever found to separate the object from background is to arrange for the objects to be entirely brighter or darker than the background. This requirement so severely limited the range of potential applications that, before long, other methods for pattern recognition were developed.
Normalized correlation (NC) has been the dominant method for pattern recognition in industry since the late 1980s. It is a member of a class of algorithms known as template matching, which starts with a training step wherein a picture of an object to be located (the template) is stored. At run time, the template is compared to like-sized subsets of the image over a range of positions, with the position of greatest match taken to be the position of the object. The degree of match (a numerical value) can be used for inspection, as can comparisons of individual pixels between the template and image at the position of best match.
NC is a gray-scale match function that uses no thresholds and ignores variation in overall pattern brightness and contrast. It is ideal for use in template-matching algorithms.
NC template matching overcomes many of the limitations of blob analysis: It can tolerate touching or overlapping objects, it performs well in the presence of various forms of image degradation, and its match value is useful in some inspection applications. Most significantly, perhaps, objects need not be separated from the background by brightness, enabling a much wider range of applications.
Unfortunately, NC gives up some of the significant advantages of blob analysis, particularly the ability to tolerate and measure variations in orientation and size. NC will tolerate small variations, typically a few degrees and a few percents (depending on the specific template), but even within this small range of orientation and size the accuracy of the results falls rapidly.
These limitations were overcome partly with resampling methods that extend NC by rotating and scaling the templates to measure orientation and size. These methods were expensive, however, and by the time computer cost and performance made them practical, they were superseded by far superior geometric methods.
The Hough transform recognizes parametrically defined curves such as lines and arcs, as well as general patterns. It starts with an edge-detection step, which makes it more tolerant of local and nonlinear shading variations than NC. When used to find parameterized curves, the Hough transform is quite effective; for general patterns, NC may have a speed and accuracy advantage, as long as it can handle the shading variations.
Geometric pattern matching (GPM) has replaced NC template matching as the method of choice for industrial pattern recognition applications requiring high accuracy or tolerance of large changes in shading, orientation or size. Template methods suffer from fundamental limitations imposed by the grid nature of the template itself. Translating, rotating and sizing grids by noninteger amounts requires resampling, which is time-consuming and of limited accuracy. This limits the pose accuracy that can be achieved with template-based pattern recognition. Pixel grids, furthermore, represent patterns with grayscale shading, which is often not reliable.
GPM avoids these limitations by representing an object as a geometric shape, independent of shading and a discrete grid. Sophisticated boundary detection is used to turn the pixel grid produced by a camera into a conceptually real-valued geometric description that can be translated, rotated and sized quickly and without loss of fidelity. When combined with advanced pattern training and high-speed, high-accuracy pattern-matching modules, the result is a truly general-purpose pattern-recognition and -inspection method.
A well-designed GPM system should be as easy to train as NC template matching, yet offer rotation, size and shading independence. It should be robust under conditions of low contrast, noise, poor focus, and missing and unexpected features.
Pattern-recognition time is application specific, which is typical of image analysis methods. For example, to locate a 150 × 150 pixel pattern in a 500 × 500 field of view with 360° orientation uncertainty might require under 20 ms on PCs operating in the 2-GHz range. Always test speed for a specific application, however, since times can vary considerably beyond any specified range.
GPM is capable of a much higher pose accuracy than any template-based method, as much as an order of magnitude better when orientation and size vary. Table 2 shows what can be achieved in practice when patterns are reasonably close to the training image in shape and not too degraded. Accuracy is often higher for larger patterns; the example of Table 2 assumes a pattern in the 150 × 150 pixel range.
TABLE 2.
GEOMETRIC PATTERN-MATCHING ACCURACY
| |
|
Translation |
|
±0.025 pixels |
|
| |
|
Rotation |
|
±0.02 degrees
|
|
| |
|
Size |
|
±0.03 percent |
|
150 x 150 pixel pattern
Like all pattern-recognition methods, GPM accuracy is highly application dependent. Accuracy cannot be specified in advance, but must be measured on actual samples. Furthermore, GPM accuracy is notoriously hard to measure because it is extremely difficult to know the true position and orientation of an object to high enough accuracy. If high accuracy is important, working with an experienced vendor is strongly recommended.
GPM is also capable of providing detailed data on differences between a trained pattern and an object being inspected. These different data are also independent of rotation, size and shading.
Putting it all together
Often, a complete digital image processing system combines many of the above image enhancement and analysis methods. In the following example, the goal is to inspect objects by looking for differences in shading between an object and a pretrained, defect-free example, called a golden template.
Simply subtracting the template from an image and looking for differences does not work in practice, because the variation in gray scale due to ordinary and acceptable conditions can be as great as that due to defects. This is particularly true along edges, where slight — or subpixel — misregistration of template and image can give rise to large variations in gray scale. Variations in illumination and surface reflectance also can give rise to differences that are not defects, as can noise.
A practical method of template comparison for inspection uses a combination of enhancement and analysis steps to distinguish shading variation defects from that resulting from ordinary conditions:
- A pattern recognition step (e.g., GPM) determines the relative pose of the template and image;
- A digital resampling step uses the pose to achieve precise alignment of template to image;
- A pixel mapping step using histogram specification compensates for variations in illumination and surface reflectance;
- The absolute difference of the template and image is computed;
- A threshold is used to mark pixels that may correspond to defects. Each pixel has a separate threshold, with pixels near the edges having a higher threshold because their gray scale is more uncertain;
- A blob analysis or morphology step is used to identify those clusters of marked pixels that correspond to true defects.
Further reading
Digital image processing is a broad field with extensive literature. This introduction could only summarize some of the more important methods in common use and may suffer from a bias toward industrial applications. We have ignored image compression, 3-D reconstruction, motion, texture and many other significant topics.
The following are suggested for further reading. Ballard and Brown gives an excellent survey of the field, while the others provide more technical depth.
Ballard, D.H., and C.M. Brown (1982). Computer Vision. Prentice-Hall, Englewood Cliffs, N.J.
Horn, B.K.P. (1986). Robot Vision. MIT Press, Cambridge, Mass.
Pratt, W.K. (1991). Digital Image Processing, 2nd Ed. John Wiley & Sons, New York, N.Y.
Rosenfeld, A., and A.C. Kak (1982). Digital Picture Processing, Vols. 1 and 2, 2nd Ed., Academic Press, Orlando, Fla.