A growing number of configurable machine vision software platforms on the market support the analysis of 3D data, making processing more accessible without the use of low-level code.
DAVID DECHOW, MACHINE VISION SOURCE
A wide range of applications in industrial
automation require and are enabled by 3D imaging. 3D technologies
are in demand in varied industries, including aerospace, automotive, logistics, and more. Components and software that deliver high-quality 3D data have evolved in recent years and the result, in many cases, has been an advancement in image quality, resolution and precision, ease of use, and greatly expanded reliable and robust use cases.

Images are commonly perceived as flat representations. Renderings of a 3D point cloud offer enhanced information of a scene. Courtesy of David Dechow.
In this context, 3D imaging is a
subset of machine vision, which leverages many imaging techniques to perform automated inspection, robotic guidance, online metrology, and other tasks to support and improve a diverse set of processes. While 3D imaging
has broad value in other areas, this
discussion will focus on how it works and is used in an automation environment.
Background and techniques
Images are commonly thought of as flat or 2D representations of a scene. The features in the image are separated mostly by differences in contrast and brightness, and more specifically by color or texture. Interestingly, the human eye can intuitively perceive or assign depth to things in a 2D representation based on a priori knowledge of the content (although even the human eye can be easily fooled).
On the other hand, imaging components that capture 3D information provide topographical data representing the surface geometry of the scene in which objects or features are differentiated by changes in relative height. It is important to note, however, that with one key exception, 3D imaging implementations rely on 2D images to construct the 3D data, and in many cases, the extraction of the 3D information is highly dependent on specialized lighting techniques. More specifically, all imaging requires illumination without exception, but with 3D imaging, illumination can be a key part of the overall system or component.

Passive stereo imaging, a 3D-imaging technique. Courtesy of David Dechow.

Active stereo imaging with random structured light, for one or two cameras. Courtesy of David Dechow.
Therefore, the critical characteristic of a 3D image for machine vision is that the image information represents calculated points in real-world space. These points may be relative to the camera orientation, calibrated to a known world coordinate system — especially when the information is used in guidance, for example — or simply analyzed relative to each other to extract features and defects, and to perform 3D measurements. Note that a 3D image provides a profile of only the surface of the scene as viewed by the camera. A 3D imaging system does not “see” the entire object on all sides, although that can be accomplished using multiple imaging devices or by moving the object in front of the 3D imaging system in a process called 3D reconstruction.
The execution of 3D imaging is by
no means new and has been implemented in automated applications for decades. However, technologies and components for 3D imaging have unarguably evolved during the years with notable recent advancements; one outcome is a clear definition of fundamental implementation techniques that differentiate products within the marketplace. These techniques are sometimes described at a very high level by whether the illumination used is active or passive, terms which refer respectively to lighting that contributes directly to the extraction of 3D information or lighting that provides contrast in the 2D scene. Some of the more common methods of acquiring 3D information from images for industrial automation include:
A single camera with passive
illumination. This technique uses
perspective to calculate the 3D position of a specific object that has rigid
features that are known in advance.
A stereo (binocular) camera pair with passive illumination. Stereo imaging involves the use of two cameras to analyze a single view from different perspectives, much like human eyes. Through proper calibration of the cameras, the geometric relationship of the two different sensors is defined relative to a fixed world coordinate system.
The cameras locate the same (or corresponding) target feature in each field of view and apply transforms to determine the position of that point in 3D space. However, only features highlighted by the passive illumination can be compared. In this manner, stereo imaging can produce a 3D point cloud of the scene, although the data of the full image might not be valid.
A light line or “sheet of light.” These components use a single line of light (active illumination) and triangulation to construct a complete 3D representation of a scene by scanning as the camera or an object is in motion. This imaging technique produces relatively dense 3D information. Commonly called profilometers or depth imagers, these systems are used in a wide variety of applications.
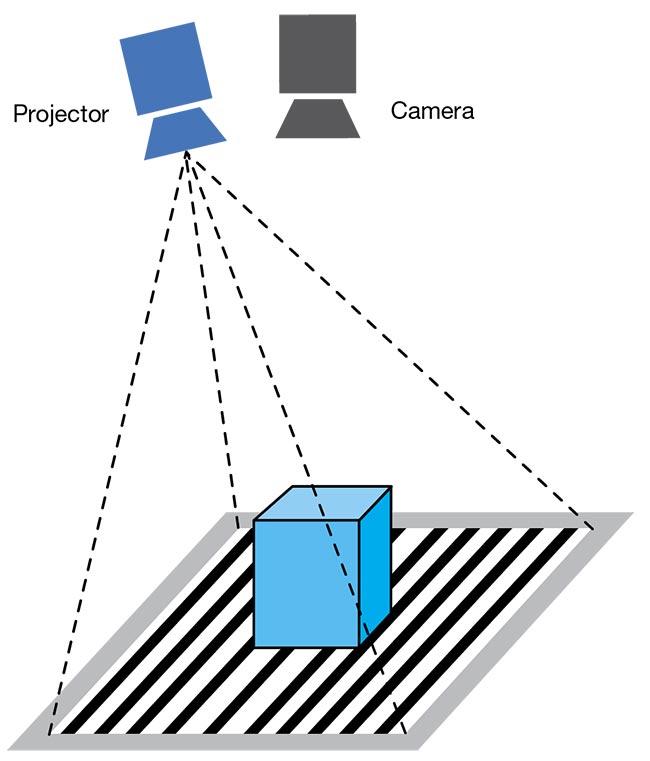
A structured light. This active illumination technique uses a structured light pattern and one or two cameras to image the pattern in the scene and construct the 3D data using varying algorithms. The light patterns range from simple dots to complex dynamic coded patterns to achieve more data points and precision. The calculation of the 3D information may use techniques similar to those found in binocular or line light imaging. In this implementation, the imaging system and part are not moving, and acquisition times are relatively fast.
A single- or multi-camera height from focus, shape, and shading. Using either active or passive illumination, these imaging techniques sometimes require less-complex components but often more complex algorithms. In certain implementations, the 3D information might be relative to the features in the scene rather than to a calibrated real-world space.
Time of flight, lidar, ladar. Time of flight is similar to implementations of lidar or ladar (light or laser detection
and ranging), and also might be referred to by some as flash lidar. This imaging is the exception to the use of general 2D sensors for 3D in that it uses specialized imaging sensors and/or camera processing to calculate a distance for each pixel by timing pulsed or phase modulated light reflections (usually infrared or even laser). Imaging speed can be very fast, but the image resolution and distance accuracy might be less than other 3D methods.
Deciding which technique(s) and components to use requires the understanding of the type of information that is available from a 3D image and what would be most useful for the target
application. In general, three types of 3D image data could be available in typical machine vision applications: single point location, depth/range
images, and point cloud representation.

Line or “sheet of light” triangulation using one or two cameras. Courtesy of David Dechow.

A structured light random dot pattern using one or two cameras. Courtesy of David Dechow.
For a 3D scene, it is not too difficult to imagine it as a huge collection of individual points, called a point cloud. Each point has an x, y, and z position
in space. With a point cloud data representation, further processing is completed, for example, to extract a single point in the scene (such as the highest point above a plane); isolate features or objects based on spatial height relative to a plane for measurement or quality evaluation; or to search for and provide the location of objects in a complex scene based on a stored 3D model of the object’s shape, often for the purpose of robotic guidance. Segmenting and analyzing features in a point cloud is performed using specialized algorithms designed specifically to work within the point cloud data representation.
The point cloud can also be represented as a depth or range map, because the z component of each point is usually the distance between the feature and a relative or user-defined plane, depending upon the imaging technique and components that are used. In some components, only the depth image is processed and 2D algorithms are often used because the pixels have simple single-valued content, except that the pixel intensity is relative to distance, not contrast or color. Even when working a full point cloud, the system might just use the
z image and simpler algorithms as part of the overall image analysis.
Single points
The data from a 3D scene comprises only the position of individual points related to specific features or objects. Often, less computational expense is required to extract single point locations, resulting in faster processing. Position and height information from a single point can be used in an application, though multiple individual points are often processed to further define an object’s spatial orientation and size for location and/or quality inspection. This processing might be based on 3D models and, more recently, might even use AI-based deep learning techniques for object segmentation and localization, particularly in the case of robotic guidance in applications such as
random bin picking.
How the data are used depends on the application. In any case, a single, unprocessed 3D image point (point cloud or depth image) provides an x, y, and z position relative to a plane. When combined with other related points associated with an object or feature, the data available to the application are a point or points with full 3D planar representation: x, y, and z position, and angles related to the yaw, pitch, and rotation — known as W, P, R: rotations about the x, y, and z axes of an object.

A depiction of time of flight imaging (top). Structured light coded light patterns for one or two cameras (bottom). Courtesy of David Dechow.
The discussion has so far considered
the background and evolution of
modern 3D imaging components. These imaging systems have matured significantly in recent years. Some of the advancements that furthered the use of 3D imaging include:
• Improvements in imaging techniques that deliver higher resolution and more precise data in the 3D image, faster acquisition times, and the ability to image moving objects.
• A wider selection of options and features to provide users and integrators with the flexibility needed for
varying applications.
• Better standardized interfacing
to software and programming libraries.
• Increased control and adjustment of image parameters to tune the response for specific tasks.
However, one of the more compelling trends anecdotally is a subtle movement from sheer do-it-yourself imaging with available components to a focus on application solutions. To be clear, the 3D imaging components in today’s marketplace are more powerful and easier to use than ever. The migration toward applications shows promise in expanding 3D imaging’s use cases and capabilities to a broader automation audience.

An actual view of a structured light pattern for 3D image acquisition. Courtesy of David Dechow.

The same image without the light pattern. Courtesy of David Dechow.

A 3D representation of random objects in a bin for robotic guidance. Courtesy of David Dechow.
On one end of the spectrum, many configurable machine vision software platforms have introduced or significantly increased their offering of basic tools that support the analysis of 3D content. The result is that the processing is accessible without working with low-level code, which had been the case as 3D imaging grew. It also means that engineers who are familiar with standard platforms can reduce the learning curve associated with 3D image processing. In some cases, development platforms are somewhat component agnostic, allowing the end user or integrator to select the imaging component most suited for the target tasks.
In a broader move, certain vendors are focusing on very specific applications and providing off-the-shelf,
targeted 3D turnkey solutions, sometimes called application-specific
machine vision solutions.

A typical representation of a 3D point cloud. Courtesy of David Dechow.

The same point cloud merged with grayscale texture. Courtesy of David Dechow.

An image showing a defect in 3D using profilometry. Courtesy of David Dechow.
While the applications vary, a noticeable surge in this type of solution can be seen in 3D vision-guided robotics (VGR), and particularly for robotic
applications in mixed or homogeneous random part bin picking and palletizing/depalletizing tasks. The promise of application-specific solutions is that the project can be implemented with little or no configuration or programming, and generally supported and maintained without expert technical staff. To be fair, since these systems have only recently emerged, it might be too early to predict their overall performance,
but initial observations seem to show good results. Note too that these applications are somewhat tightly constrained to deliver optimal results for a very specific use. A good best practice in considering this type of system would be to clearly analyze and document the needs of your application, and then research the system’s proven capabilities based on those specific needs.
Key applications
The following are common 3D application areas along with some implementation notes and best practices:
• Metrology and defect detection
3D components that are particularly well suited for 3D measurements and defect detection are available. A key component candidate in these systems is one that uses scanning and laser triangulation (e.g., a depth sensor). They are usually higher-resolution systems in terms of x, y, and z accuracies and have somewhat limited fields of view, which requires the sensor or part to be in motion to capture images. Integration techniques are similar to those used for line-scan cameras (although distance sensors in this context are not line-scan imagers).
The imaging tools and algorithms commonly used may include both standard 2D and targeted 3D tools to provide measurements including depth and sometimes position and detection of defects.
Additional 3D components might also be used, but in all cases, it is important to qualify the required feature size for defect detection and the proper resolution for metrology.

A 3D representation of a random pallet of boxes for a vision-guided robotics (VGR) pick. Courtesy of David Dechow.

A random box pallet with a 3D view. Courtesy of David Dechow.
• Robotic guidance and object location
The benefit of using 3D in robotic
guidance is the ability to locate an object in any orientation and spatial position. This kind of flexibility provides greater opportunities for VGR in a growing base of applications. Objects that are not resting in a specific plane can be reliably located for picking or processing, potentially even when they are randomly stacked or piled. A broad range of automation applications in assembly, packaging, machine-tending, and many others can have greater flexibility with 3D guidance, and most industries, including automotive, metal fabrication, and logistics and distribution, profit from the use of this VGR technology. The technology is indicated in most situations in which an object must be located at different heights and/or in different poses or stable resting states in a view.
Bin picking and palletizing/depalletizing has been mentioned but the possible use cases are much broader than those. One important consideration for VGR is to be sure that the application requires 3D imaging. When objects can present and be gripped from just a few stable resting states, it might be less complex and less costly to use 2D guidance with more flexible object detection and grip configurations.
The evolution of 3D imaging in
industrial automation opens the door for more flexible automation, which is the cornerstone of the broader offer for
machine vision technology. While 3D imaging can require significantly more effort in implementation and integration
than 2D imaging, advancements in components and self-contained systems on the market may make the technology easier to use, though
certain restrictions may arise in
exchange. Examine the possibilities
by clearly defining the scope of the project based on the needs of the
automation and seek out the best
solutions based on the capability of
the components and software.
Meet the author
David L. Dechow is an engineer, programmer, and technologist widely considered to be an expert and thought leader in the integration of machine vision, robotics, and other automation technologies; email: [email protected].